JetStream Anti-Patterns: Avoid these pitfalls to scale more efficiently

NATS was designed to be lightweight, efficient, and scalable. But distributed systems have inherent complexities - including the humans designing and building them - that can’t be solved entirely by code. So when it comes to scaling NATS, architecture and application design choices are critical to stability.
In this series, we’ll review some of the scaling anti-patterns that most commonly cause NATS server instability or slow-down. In this first post, we’ll focus on pitfalls to avoid when scaling JetStream consumers.
Another distributed systems truism: it’s more straightforward to walk through what not to do than to give a specific configuration or pattern that will always work. At scale, each use case has its quirks and there is no single ideal configuration.
If you’d like a custom review of your NATS architecture, from the experts who contributed to this piece, get in touch here.
Using Consumers at Scale
JetStream consumers are a powerful and flexible aspect of NATS. They allow clients to consume state, whether it comes from a stream, key-value bucket, or object store. Consumers can be ephemeral and are simple to create and remove quickly. Fleet management use cases love consumers for these reasons. But, at very high rates of consumer usage, certain operations are expensive and can cause locking in NATS servers.
Anti-pattern: Overusing consumer info
The consumer info call is one of those potentially expensive operations. Why? Let’s review what it actually does.
It fetches a list of metadata about a specific consumer, including configuration and state information:
1$ nats consumer info ORDERS DISPATCH2Information for Consumer ORDERS > DISPATCH3
4Configuration:5
6 Durable Name: DISPATCH7 Pull Mode: true8 Subject: ORDERS.processed9 Deliver All: true10 Deliver Last: false11 Ack Policy: explicit12 Ack Wait: 30s13 Replay Policy: instant14 Sampling Rate: 10015
16State:17
18 Last Delivered Message: Consumer sequence: 1 Stream sequence: 119 Acknowledgment floor: Consumer sequence: 0 Stream sequence: 020 Pending Messages: 021 Redelivered Messages: 0In a vacuum, it’s not inherently expensive. But consumer info was intended to provide insights for monitoring or debugging.
When the consumer info call is repeatedly used at scale, it creates expensive overhead. Consumer info has to go to the meta-leader before it returns a “does not exist” error and, if the consumer does exist, requires calculating state.
If you only want to know whether a consumer exists, those expensive state calculations were wasted. And at scale, that waste can add up.
A pattern like this:
- consumer info call
- consumer doesn’t exist > consumer create
- consumer does exist > consumer update
which seems innocuous in a prototype or proof of concept, becomes very expensive across ten of thousands of clients.
Using consumer info to check if a consumer exists is unnecessary. Instead, just call consumer create
Using consumer create
When creating a consumer, if the consumer already exists with the same name on the specified stream, JetStream verifies the request against the existing consumer’s config. If they match, the call is idempotent and JetStream responds with a success message without making any changes.
If the config differs, JetStream will update the existing consumer (unless the operation tries to update a non-editable configuration, e.g. start sequence, in which case an error is returned). When the consumer doesn’t exist, a new one is created with the specified config.
Check Pending JetStream Messages
Consumer info is also frequently misused as a method for clients to check for pending messages. Instead, get this metadata from the last message fetched to avoid the unnecessary overhead of consumer info. What’s available in message metadata?
1type MsgMetadata struct {2 // Sequence is the sequence information for the message.3 Sequence SequencePair4
5 // NumDelivered is the number of times this message was delivered to the6 // consumer.7 NumDelivered uint648
9 // NumPending is the number of messages that match the consumer's10 // filter, but have not been delivered yet.11 NumPending uint6412
13 // Timestamp is the time the message was originally stored on a stream.14 Timestamp time.Time15
16 // Stream is the stream name this message is stored on.17 Stream string18
19 // Consumer is the consumer name this message was delivered to.20 Consumer string21
22 // Domain is the domain this message was received on.23 Domain string24}Anti-pattern: Too many consumers
Because of all their advantages, it’s tempting to overuse consumers. But consumers do have overhead costs (managing state, replicating it across the cluster) and beyond a certain threshold instability or failures are likely.
How many consumers is too many? There’s no hard cap, but beyond 100,000 consumers, the potential for issues increases significantly. The background Raft traffic and the load on the meta-leader increase as they work to maintain state consistency across nodes and manage consumer subscriptions. Eventually this increased overhead is too much.
Fortunately there are alternate design patterns that can greatly reduce how many consumers you use.
Replacing consumers with republish
For example, republish. Imagine a stream called orders with three different consumers for filtering different order types:
orders.type.electronicsorders.type.furnitureorders.type.clothing
Again, this approach works, until you consider the overhead of managing state for 100K+ consumers.
With republish, we can combine core NATS and JetStream, to get to nearly the same outcome, without the consumer overhead, by adding a republish policy to our orders stream:
1{2 "republish": {3 "source": "orders",4 "destination": "filtered.orders.>"5 }6}Messages are republished to subjects like filtered.orders.electronics, filtered.orders.furniture, and so on. Then subscribers listen for messages on those subjects.
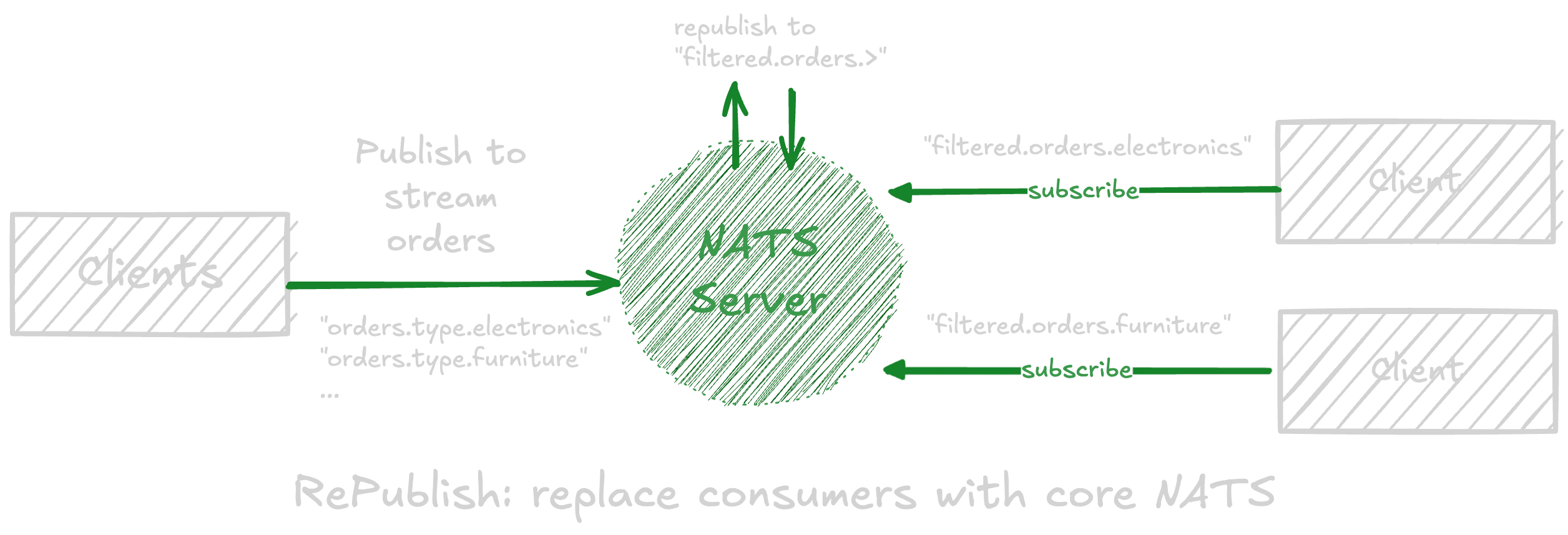
Republish is ideal for use cases where subscribers can handle messages in real time and do not require strict delivery guarantees. Often, having too many consumers is downstream of overstated persistence and delivery guarantee requirements.
Direct and Batch Get API
Another alternative to consumers: the Direct Get API. The Direct Get API is even faster and more lightweight than consumers, making it ideal for getting specific messages from streams.
For example, getting the last message on a subject from a stream via the shortcut form:
1$ nats req ‘$JS.API.DIRECT.GET.<stream>.<last_by_subj>’ ‘’This pattern is especially useful for mobile or IoT applications that target specific subjects and want to fetch only the latest data (minimizing network overhead and local processing).
In 2.11, this capability is becoming even more useful. With Batch Get, you can return multiple messages from multiple subject filters.
Anti-pattern: Too many subject filters on a single filter consumer.
In 2.10, the ability to specify multiple subjects in a single server-side consumer filter was added. These subjects don’t have to follow a common pattern or share a hierarchical structure—they can be completely disjoint. Another example of the power and flexibility of consumers.
Again, there is no hard limit here. But adding more than a few hundred disjoint subject filters will likely lead to slowness and instability.
As more disjoint subjects are specified, more subject indexing and matching operations increase server-side workload. Each additional disjoint subject filter potentially requires the loading and scanning of more message blocks to identify matches, which can degrade consumer performance and overall system efficiency.
Instead of excessive disjoint subject filters on a single consumer, you should:
- use separate consumers, each with a reduced number of subject filters
- re-evaluate your subject name hierarchy so you can better leverage wildcard filters
Recap
If you leverage JetStream strategically—and steering clear of inefficient usage patterns—you can maintain high performance and stability in your NATS server.
Key Takeaways:
- Avoid overusing consumer info calls; use consumer create or metadata in the last fetched message instead
- Reduce the total number of consumers below ~100k to prevent excessive overhead and potential server instability
- Use alternatives like republish and the Direct Get API to avoid unnecessary consumers
- Keep disjoint subject filters manageable—less than ~300—on each consumer to minimize indexing and matching overhead
If you’d like advice from the experts as you design or refactor your JetStream usage patterns, get in touch here.
Related posts
All posts


