NATS for Retail: Manage Thousands of Nodes at the Edge by Reducing East-West Traffic

In distributed systems, one way of describing the flow of data or traffic is north-south vs east-west. These terms refer to the direction in which traffic flows between network locations, boundaries, and devices.
When working with edge systems, understanding these foundational concepts helps in designing efficient, scalable systems. This is especially true when a system has thousands of nodes.
Recently, a retail company exploring NATS for their edge retail use case asked this question:
We plan to install a NATS leaf node in each of our [thousands of] stores, all connected to a central cluster hosted at our cloud provider. The data exchanges will be between the stores and the central cluster, with no communication occurring between stores directly. We intend to use JetStream source and mirror to synchronize data between the stores and the central cluster. This will help our in-store applications become more resilient to connectivity issues.
However, managing all the leaf nodes is a significant concern, particularly due to the potential increase in NATS gossip between all nodes.
This setup is a classic example of a north-south topology. In this case, data flows between the edge (stores) and a central hub (the cloud cluster), with no direct store-to-store communication.
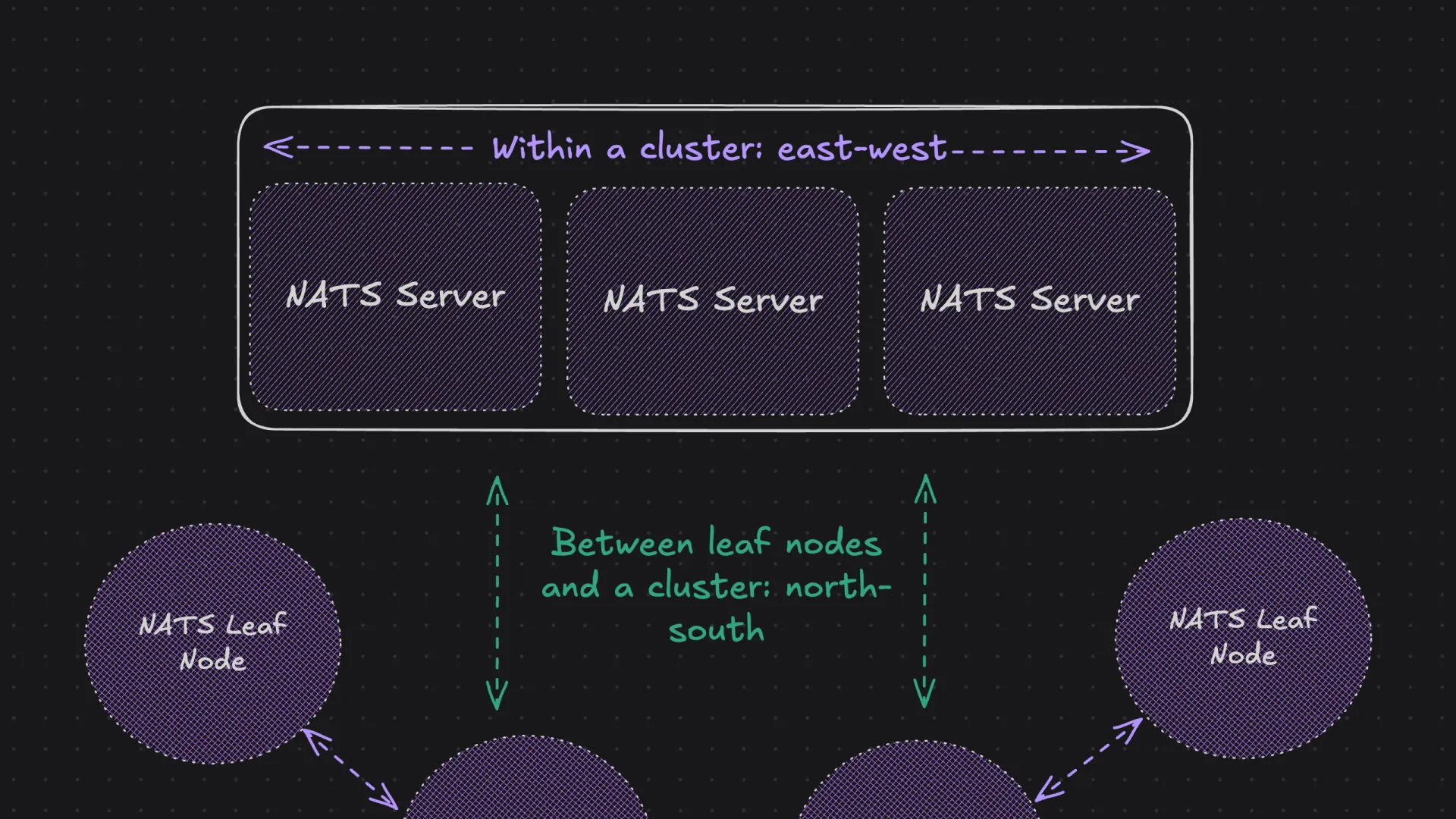
What is the difference between North-South and East-West Traffic?
North-south traffic refers to communication between different layers or network boundaries.
In this example, communication between the store leaf nodes and the centralized cloud cluster is north-south traffic. This is the primary path of data flow in typical edge architectures.
East-west traffic describes communication within a layer or network boundary.
In this example, subscription info and other meta-data being passed between leaf nodes (i.e. the “NATS gossip” referenced above) represents east-west traffic. This pattern is used when edge nodes need to share data directly—which isn’t actually what the retailer wants in this case. Generally, this is less common in standard hub-and-spoke topologies.
Traffic Flows
Traffic in NATS depends on the topology, but in the simplest terms, traffic is point-to-point between each type of NATS component in the topology. Components are loosely defined as either clients or servers.
A client contains the NATS client library (available in more than 45 languages), plus custom application code. This could be any custom service or a tool like the NATS CLI. A server is a nats-server or a nats-server configured as a leaf-node. Traffic, therefore, flows:
- north-south
- between clients and servers
- between leaf-nodes and servers
- east-west
- between servers in the same cluster
- between clusters of servers in the same super-cluster
- between leaf-node servers in the same cluster
Challenges in Managing Large-Scale Leaf Node Deployments
Ultimately, the retailer’s concern about managing thousands of leaf nodes is valid. While NATS leaf nodes generally do not communicate directly with one another unless there’s legitimate interest (i.e., no east-west traffic by default), they can still generate east-west network overhead through subscription propagation when using JetStream.
This is particularly noticeable during startup, where new leaf nodes receive subscription updates from other nodes. By default, when the Nth leaf node starts, it receives N-1 leaf subscriptions.
How to Optimize North-South Architectures in NATS
In order to minimize subscription propagation between stores, a useful trick is to configure all leaf nodes to have the same cluster name.
This prevents the cloud/hub cluster from managing unnecessary interest graph propagation between individual leaf nodes. With this setup, the leaf nodes in retail stores at the edge won’t communicate with each other and won’t generate any unnecessary network overhead.
This capability will be formalized in the 2.11 release of NATS.
North-South Architectures in Edge Computing
For edge deployments like this retailer’s setup, eliminating unnecessary east-west communication simplifies their architecture and minimizes network overhead. Each store’s leaf node only interacts with the central cluster, making the system scalable and easier to manage.
With its efficient subject-based addressing and the ability to isolate communication, NATS reduces the complexity often seen in large-scale edge deployments.
NATS’ ability to function autonomously at the edge also provides resilience in cases where nodes may have intermittent connection to the central system: data can be buffered locally and ready to sync seamlessly back to the hub upon re-connection. This makes NATS north-south topologies ideal for distributed systems where edge nodes (point of sale applications, automated manufacturing, IoT devices, autonomous vehicles, etc.) can’t drop data and need consistent local functionality even when disconnected from their cloud hub.
For any organization considering large-scale edge deployments, NATS offers the tools and flexibility needed to efficiently manage these architectures. Need help fine-tuning or scaling your NATS architecture? Get in touch with our experts.
Related posts
All posts


