Connecting distributed SCADA with NATS.io (part one)

It’s impossible to have an industrial control conversation without talking about Supervisory Control & Data Acquisition (SCADA). It was around in the 1970s and despite a handful of technological advancements, it’s still familiar and recognisable to anyone who stopped paying attention. SCADA is applicable to industrial process automation patterns and the list is huge, but examples include manufacturing lines, road junction turnings, power distribution and railways. At the heart of these systems are Programmable Logic Controllers (PLCs), which can take readings from physical sensors, make decisions and manipulate outputs to control connected components. PLCs evolved from racks of electrical components like relays, circuit breakers and contactors that electricians designed and maintained with wire links. They were not easy to change and required some skill.
SCADA is an architecture and pattern split into levels:
-
Level 0 is where you will find sensors and actuators, like temperature and flow sensors, motors and solenoids
-
Level 1 is about the first point of distributed control in the form of PLCs
-
Level 2 contains supervisory computers which provides information for supervisor screens
-
Level 3 contains production control systems like monitoring production targets
-
Level 4 is focused on production scheduling
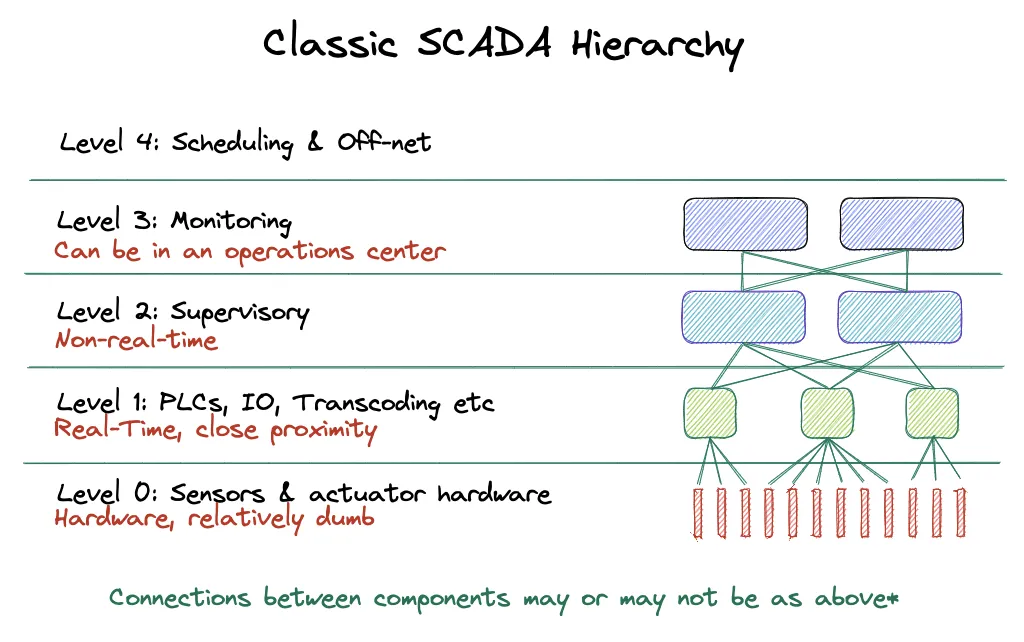
Classic SCADA layers
In summary, SCADA can be represented as software running on computers and servers, human interface systems, PLCs, inputs (sensors) and outputs (actuators).
A little like IT automation workflow engines, the whole point of PLCs is to distribute control of a process away from a central computer so real time decisions and adjustments can be made to the process the PLC is controlling. The process could be a beer bottling facility, power distribution or a railway junction. Logic dictates the need to monitor, observe and track processes across an organisation’s estate is of paramount importance for operations, safety, reliability, product output, optimisation, billing and troubleshooting reasons. The saying “It’s software, no one died”, isn’t applicable in this field.

The Siemens S7-1500 family PLC, Copyright Siemens
PLCs enabled an army of electro-mechanical engineers to build complex systems and have stood their ground as an economically priced control point. They have gained performance capabilities as CPU, memory and storage continue to drop in price and it’s no surprise then that companies utilising this technology like utility, manufacturing and transport, to name but a few, have islands of automated control systems strewn across counties, states, countries and continents. To make matters more interesting, these devices vary in age, manufacturer and capabilities.
PLC Programming Languages, Protocols, and Why Classic SCADA Stops Scaling
These are some of the original requirements of the PLC laid out by the Hydra-Matic division of General Motors back in 1968:
-
A solid-state system that was flexible like a computer, but priced competitively with relay logic system
-
Easily maintained and programmed inline with the already accepted relay ladder logic way of doing things
-
It had to work in an industrial environment with dirt, moisture, electromagnetism and vibration
-
It had to be modular in form to allow for easy exchange of components and expandability
PLC programming languages; source IEC-61131_3
PLC programming started out with ladder logic because that’s the way engineers at the time implemented industrial process control. Power flowed from the left, passing through relay style contacts and switches, which then terminated on outputs called coils. This is very similar to working with logic gates in digital electronics.
Modern PLC programming languages include Ladder logic (LAD), functional block diagrams (FBD), instruction lists (IL) and structured text (ST) methods. To summarise this paragraph, you can approach PLC programming from an electrical background or from traditional imperative programming. Neat. If you’re curious what the programming specification looks like, it’s in a document called IEC-61131-3
Regarding operations, each vendor supports network level protocols over Ethernet & IP and these include Modbus, OPC-UA, DNP3 and vendor specific protocols like Siemens S7. If you’re used to working with REST heavy web programming, you’re in for a ride. Some of these protocols are arcane and are not security oriented, leading to poor implementation or avoidance altogether. State level threat actors in 2023 are all too real to ignore and so connecting these systems securely and easily is key.
Note that PLC software isn’t compiled and you cannot easily run a suite of unit tests. Modifying PLC programs is done by directly downloading to the PLC device and any integrations like a data fabric must take into account changes simultaneously.
SCADA offers a pattern of connectivity for components from the hierarchical diagram, but as deployments and device counts increase, having one SCADA system that’s centrally deployed and managed becomes difficult to maintain. There is a device count explosion at the edge and each industry sector has their own version of that problem. In power distribution there are millions of smart consumer meters, in manufacturing, countless numbers of sensors. Process control systems need access to this device data to make better decisions and in 2023, the industrial sector agrees that the classic model is upside down. Devices should present their data to distributed decision making logic, easily and securely without arcane protocols that offer little to no support and lack of widespread industry expertise. There is a burning need for control and analytical software to subscribe to Level 1 PLC data without exposing security sensitive devices directly to an enterprise network. Enterprise style networking topologies for this use case demand a large budget and present huge complexity and security nightmares.
Solving this requires a data fabric that:
-
Publishes data in a push manner
-
Offers command and control capabilities like request-response semantics
-
Is highly performant
-
Offers large scale fan-in and fan-out patterns
-
Transforms point-to-point IP communications to named conversations
-
Does not rely on DNS for end-to-end connectivity
You’re in luck. NATS.io has you covered.
How to Connect a PLC to NATS with Modbus
The YouTube video below demonstrates a contrived use-case in which NATS is connected to a PLC with a simple Modbus client. This client in turn authenticates to the NATS cluster and collects information from the PLC in a closed-loop transmitting the data to a NATS stream. This client is configuration driven and publishes named data that other systems can subscribe to. It also does not rely on direct protocol support from the PLC other than the simple Modbus protocol. Newer and more powerful PLCs support a wider range of protocols and building a pluggable adaptor system for your data fabric is achievable, but beyond the scope of this demo. A normalised way to think about this is presenting inputs, outputs, specific memory and tags to NATS subjects, serving connected systems through pub-sub and request-reply semantics.
The core thesis presented in this post is not to access the PLC directly from Level 2 of the SCADA stack, but to gate Level 1 components and insulate them from issues of connectivity, manageability and security. A software client accesses the Level 1 components and transmits data to NATS over a cheap cellular connection and with the persistence layer of a local TLS enabled NATS Leaf Node, it can buffer collected data and transmit it at a later time in the event of a cellular network issue.

Watch talk on YouTube
Should you immediately rip out MQTT and replace it with NATS? It doesn’t make much sense to rip out one pub/sub system for another, and that’s not where NATS shines.
Much like how IT has migrated to the cloud and multi-cloud, it should be clear at this point, SCADA systems face the same headache of connectivity. The PLCs themselves will always have to execute in close proximity to whatever process they’re running, but the state data and computed state in the form of streamed events, needs to be available enterprise wide for analytical, monitoring and process mimic systems to make sense of what’s going on. Let’s talk about a concrete use case in power distribution automation.
The Upside-Down SCADA Problem in Power Distribution
In power distribution, substations and micro-energy grids reside in many locations and each system manages the state of electrical switch-gear and multitudes of sensors. As the number of these locations increases, so do the autonomy requirements resulting in decisions being made close to the sensor source and switch-gear control point. For example, imagine a housing estate having an electrical surge issue or tree strike on power lines, a decision to burn the tree off of the lines or break the connection may need to be made. That decision might be made based on multiple sensory inputs like available capacity in the area, with the point being, a wide set of varied data is required to make that decision.
Distributed but horizontally communicating decision making systems that still fit in the hierarchical abstracted SCADA model acting on the inputs, but having an enterprise network spanning thousands of locations, all taking part in a single SCADA design, is asking for trouble. One compromised system results in chaos and the operational costs would be astronomical.
The outcome of a decision is to do nothing, or turn some switch-gear on or off. Therefore, it makes sense for the raw data to be dealt with in a distributed manner directly by PLCs and to publish the state change event to any other system that can make use of the decision and input data. A lot of other data could be shared in a local neighbourhood of substations, enabling cluster like behaviour. Let’s re-imagine SCADA with NATS!
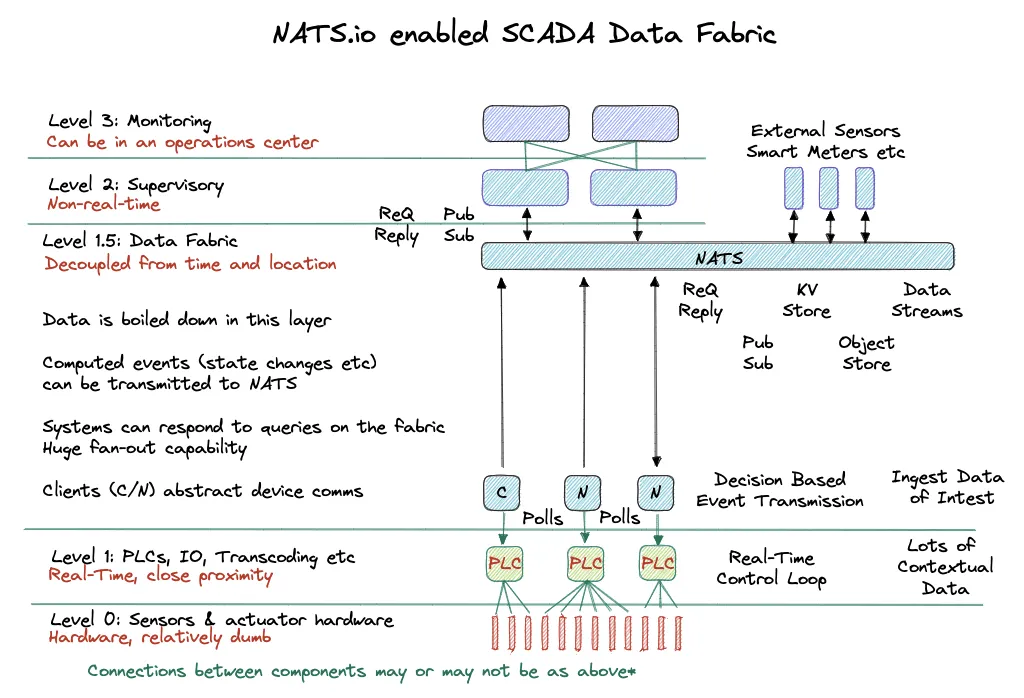
If a connected neighbourhood of substations subscribed to the very end-points they feed through smart meter technology, decision making logic can be distributed and closer to the sources of input data, enabling hive based optimisation and efficiencies. Real world numbers of smart meters are in the millions and a centralised system would be overwhelmed with this level of information. An enterprise network solution to connect these components would not provide cost effective connectivity nor the security profile required to scale. What is needed is a cheap connectivity medium with resiliency built into the system that communicates over it.
A solution to this is to have a constrained and authenticated data collection layer that securely transmits named and type specific data to a flexible messaging system. This messaging system should be able to handle slow and fast data producers and consumers, and offer high fan-in and fan-out patterns. If you’re not familiar with NATS, all the boxes are ticked so far. With a NATS solution, one lightweight and highly performant component is deployed multiple times. It can deliver publish-subscribe, request-reply, message streaming, key-value and object store semantics and it’s one system to operate and understand, placing minimal load on operations teams. Its communication requirements are simple with connected clients and leaf nodes initiating encrypted, authenticated and authorised connections to the cluster. It’s the NATS advantage.
By separating decision making code from data collection, non-real time systems like billing and prediction can live in public clouds where software developers can move rapidly. Real-time control loops stay close to the field devices and a data fabric exists to extract metrics and provide them to the layers above, without placing additional load on field devices. Extra intelligence could be built into data fabric gateways that understand the devices they connect to, which would solve unit conversion like millivolts to volts and it would also remove low level configuration requirements from the data fabric components.
The cellular industry is going through a transition of this nature in 4G and 5G systems with a split between real-time and non-real-time systems and the location of the components that interact. Some components are required to live close to a radio tower to cope with activities like radio frequency management and others like user management can live elsewhere.
Below shows a distributed SCADA system, powered by a NATS data fabric. One fabric with many conversations powers the whole solution. NATS handles the relationships between components that show interest in each other and enables ease of communication.
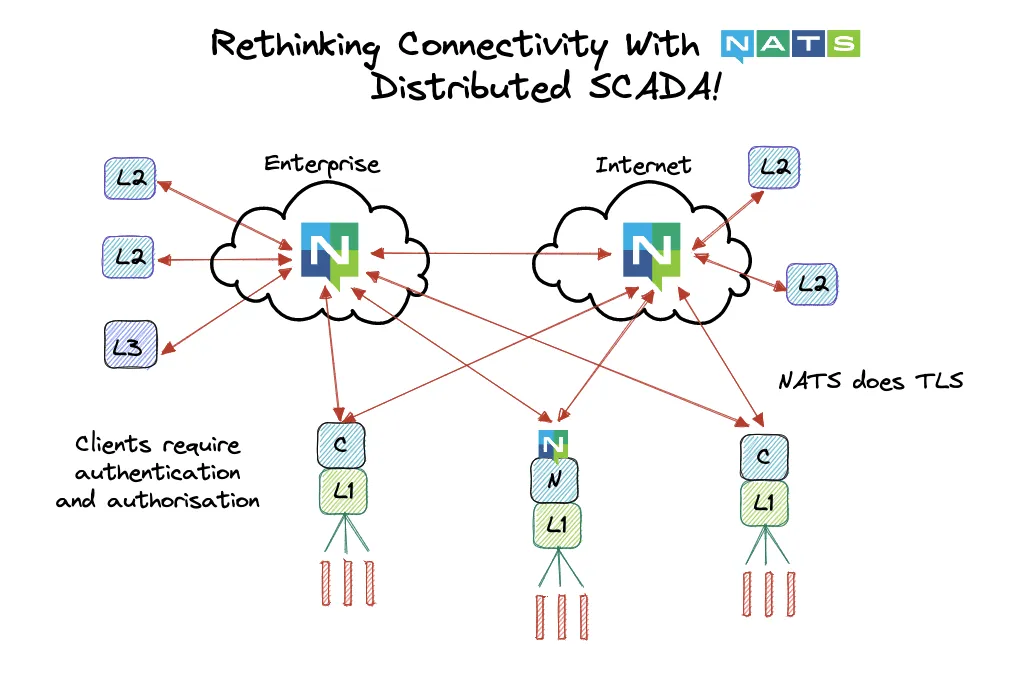
Summary: A Distributed SCADA Data Fabric with NATS
With NATS, we can transform the relationship between physical location and break the concrete SCADA model. By creating a data fabric that sits between Level 1 and Level 2, data can be published organisation wide without losing the ability to respond to solicited queries. Real-time decision making logic in PLCs remains close to the equipment they’re connected to and higher level process oriented logic like process optimisations, historians, operational systems that deal with alarms and alerts, billing and planning systems can be elsewhere. In the use case of distribution automation, local power microgrids can make use of consumer data and make optimisation decisions autonomously. Safety and operational system integrity isn’t lost either, because real-time data streams and disk or memory persisted streams can co-exist.
Thanks for reading part one and if you’re done here, that’s absolutely fine! In part two, we explore enhancing SCADA with NATS.
Related posts
All posts
